Intrarea romanilor in UE- studii
de risc seismic (partea I)
Nu va
speriati, titlul nu se refera la niste consideratii legate de vreun cutremur
provocat de intrarea
Romaniei in UE insa ce se poate spune este ca odata cu tara au intrat in UE si cladirile cu risc seismic ramase
prin cetatea lui Bucur, plasate in diverse sectoare ale capitalei.
Mi-a
atras atentia un coleg al meu preocupat de businessul asigurarilor dar si de
sperietura unui iminent
si atat de “asteptat” cutremur de pamant; acesta a
facut rost de lista de imobile, publica de altfel, care grupeaza
cladirile in 4
grupe: de la III (3) , in care respiri mai cu usurare pana la I+ (1+) unde nu
numai ca respiri greu
dar e bine sa ai niste lumanari pe aproape in caz ca …
Bun, gata
cu sperietura, mi-am propus sa studiez in acest articol legaturile dintre date
prin tehnicile de
data mining (minerit de date cum ne mai place sa le zicem)
si, de ce nu , sa fac niste interpretari asa cum
o sugereaza datele. As vrea sa
precizez (asa cum voi face la sfarsit), ca aceste consideratii sunt niste
opinii personale
care nu implica in nici un fel institutii, sisteme sau persoane etc. Revenind, intr-un articol
viitor voi studia aceeasi
problema prin tehnicile data mining de pe langa
Office 2007 precum si posibile noi interpretari ale datelor.
I.
Configurarea
studiului
Iata cum arata in niste selectiuni
datele brute aflate in 4 documente pdf:
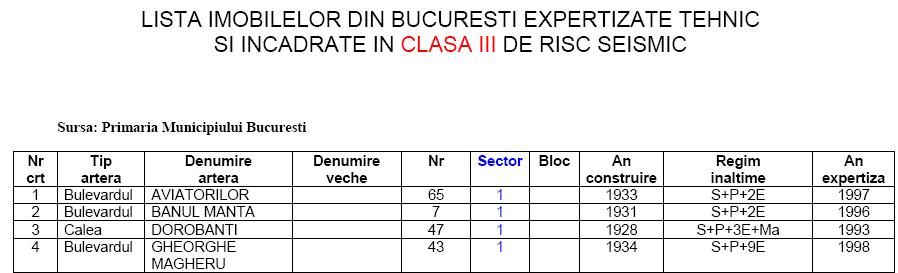
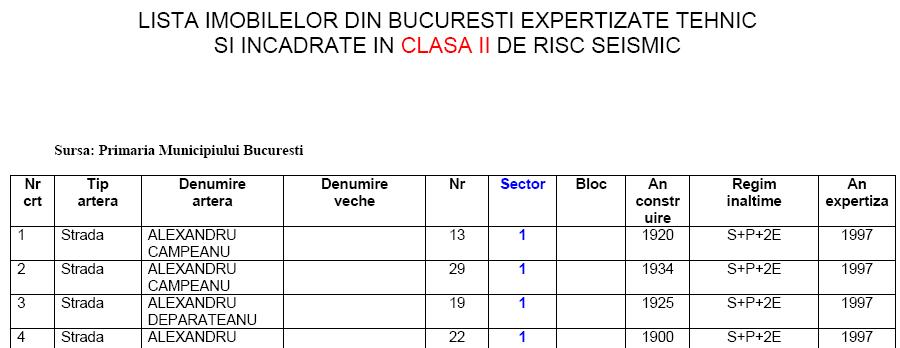
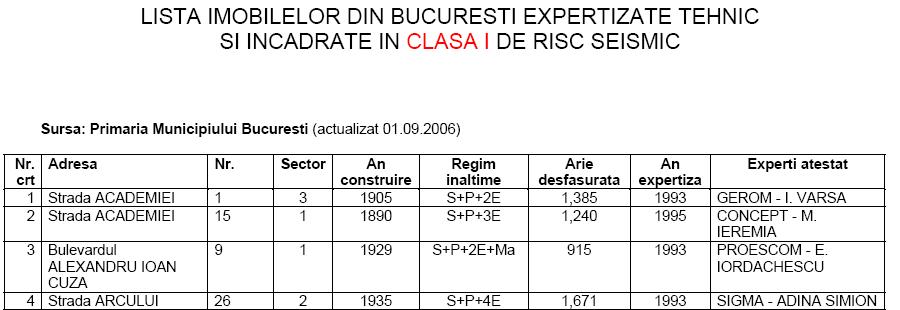
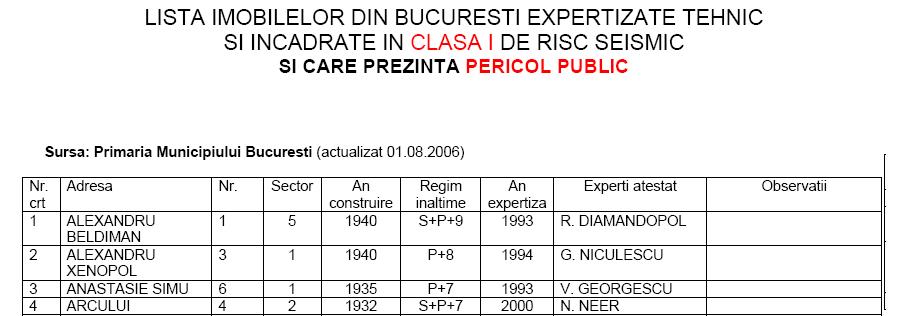
Asa cum
observati, datele din cele 4 tabele trebuie adunate si prelucrate asa cum scrie
la carte pentru a fi o
sursa de date coerente si sigure. Aduse in Excel am
facute mai multe prelucrari:
·
Am
adaugat o coloana care detine gradul de risc;
·
Am
pastrat un singur an de construire in cateva situatii (probabil acel imobil a
fost refacut in trecut) – asta nu
afecteaza coerenta studiului nostru;
·
Am
adaugat campul “Expert” care desemneaza institutia sau persoana care a
expertizat imobilul; pentru imobilele
de grad mai scazut de risc am considerat
ca expertul a fost Primaria (Capitalei);
·
Campul
“ArieDesfasurata” are valoarea 0 pentru imobilele in care nu s-a precizat asta;
·
Campul
RegimInaltime a ramas pe loc (apropos S+P+5E+Ma inseamna Subsol+Parter+5 Etaje+
Mansarda);
·
A
trebuit sa folosesc niste functii Excel ca sa omogenizez datele, de exemplu ,
imobilele cu gradul 1 aveau combinat
tipul de artera cu denumirea arterei ( ex. Strada Academiei) si a trebuit sa duc
datele in campurile corespunzatoare.
Sursa de date apare in figura urmatoare :

Mai
departe duc datele in SQL 2005 intr-o baza de date special facuta prin
mecanismul Import/Export al SSIS si aleg tipurile de date ale tabelei gazda asa
cum apare in figura urmatoare :

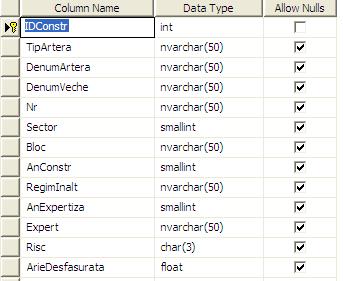
In
continuare deschid un proiect in SQL Server Business Intelligence Development
Studio . Configurez sursa de date si view-ul atasat dupa care trec , in ordine
la modelele bazate pe algoritmii corespunzatori (care sunt vizibili in figura
de mai jos)
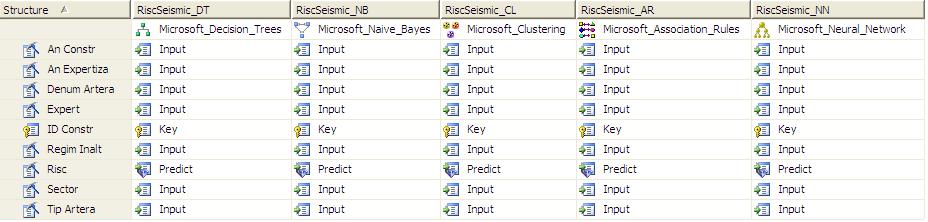
Trebuie
precizat ca IdConstr este ales drept cheia iar Risc este coloana de predictie;
An Constr si An Expertiza
au fost declarate “Discretized” astfel ca sistemul sa
formeze plaje de ani in care vor incadra constructiile respective.
Apoi trec la
procesarea datelor si sa vedem rezultatele
II Interpretarea datelor
Interpretarea
datelor o facem in mai multe parti , depinde de modul in care epuizam subiectul
dar si de eventuale ajustari ale
proiectului.
Aspectul “Dependecy Network” este vizibil , asa cum se
stie la mai multi algoritmi si, pentru o prima evaluaream grupat asa:
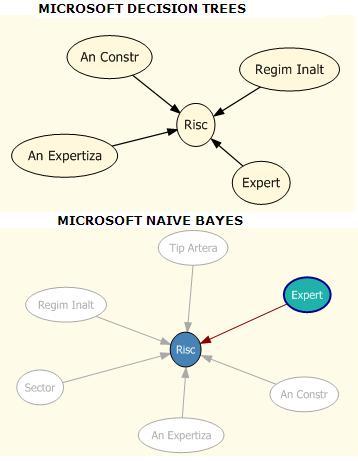
Legatura mai stransa intre Risc si celelalte atribute
incepe de la “tare” la “slab” astfel :
·
Expert,
An Constr, An expertiza, Regim Inalt in cazul Decision Trees;
·
Expert,
regimInalt, An Expertiza, An Constr, Sector, Tip Artera in cazul Naïve Bayes
Ce se vede cu ochiul liber este ca atributul Expert este
identificat ca cel mai puternic pentru ambii algoritmi,
apoi anii de
constructie si de expertiza. Daca dinspre anul de constructie era de asteptat
sa primim acest rezultat tot
ce tine de aspectele de expertiza influenteaza
atributul de risc. Sa fie oare momentul si calitatea expertizei direct
legata
de aprecierea de risc ? Ramane sa atacam aceasta problema in articolele
viitoare; oricum aspectul
Dependency Network al algoritmului Microsoft
Association Rules nu afost tratat aici datorita complexitatii sale insa
va
asigur ca da rezultate bune.
Gigi Ciubuc
Nota. Acest articol reprezinta opinii personale ale
autorului, si trebuie tratat ca atare si nu are alte implicatii.
Gheorghe Ciubuc,SQL Server Influencer, MCP(SQL 2000), MCTS (SQL Server 2005) , OCA(Oracle 9i), Sybase(Brainbench)